AlertManager和Prometheus Server一样,均采用Golang实现。并且没有第三方依赖。
AlertManager 下载地址如下
https://prometheus.io/download/
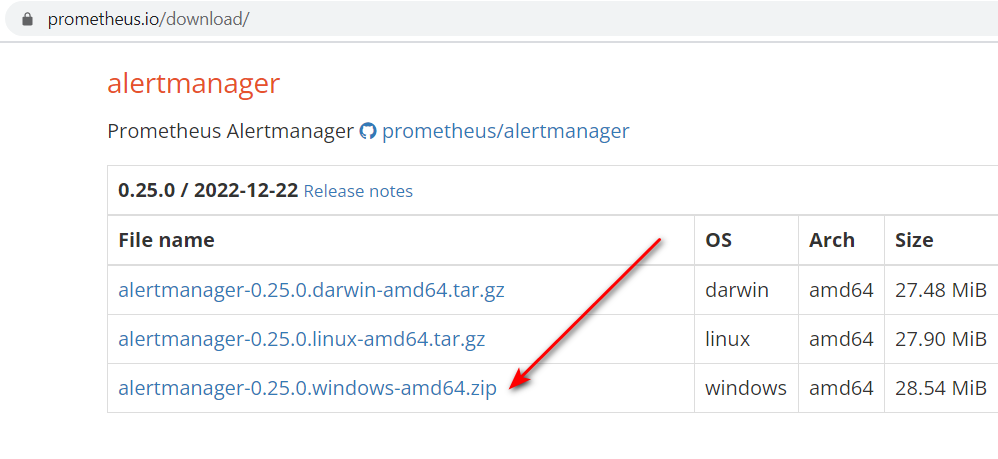
解压下载的amd64 zip文件
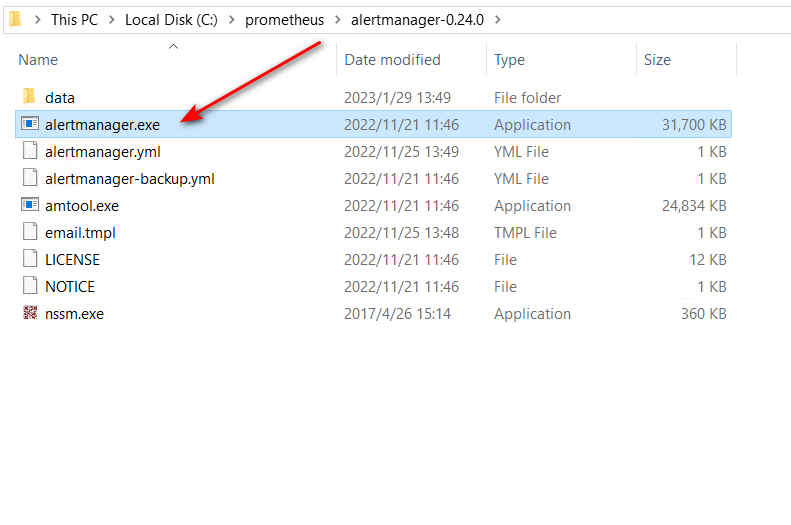
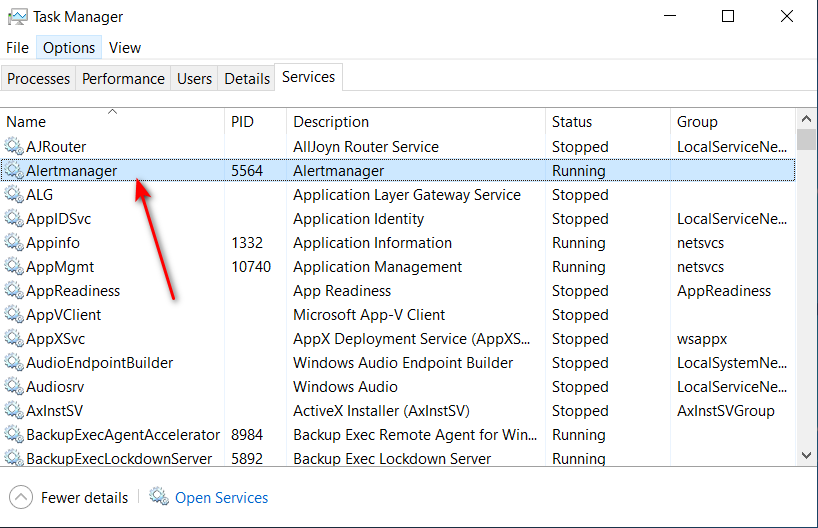
使用nssm.exe 把alertmanager.exe注册成系统服务
在浏览器打开127.0.0.1:9093 验证服务是否启动
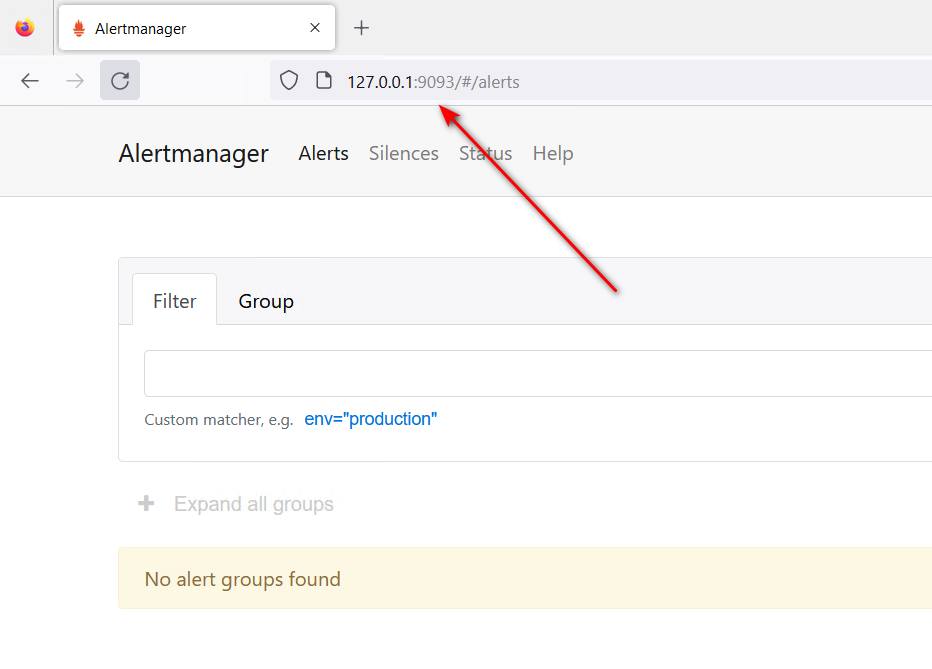
Alert菜单下可以查看Alertmanager接收到的告警内容
Silences菜单下则可以通过UI创建静默规则
Status菜单,可以看到当前系统的运行状态以及配置信息
我们来配置 alertmanager.yml 文件 (主要配置SMTP信息和email接收方信息)
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.notepad.com.cn:25'
smtp_from: 'test@notepad.com.cn'
smtp_auth_username: ''
smtp_auth_password: ''
smtp_require_tls: false
templates:
- 'email.tmpl'
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'user@notepad.com.cn'
html: '{{ template "email.to.html" . }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
接着我们创建一个 email.tmpl 文件 代码如下:
{{ define "email.to.html" }}
{{ if gt (len .Alerts.Firing) 0 }}{{ range .Alerts }}
@告警: <br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级<br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Local }} <br>
{{ end }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}{{ range .Alerts }}
@恢复: <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
恢复时间: {{ .EndsAt.Local }} <br>
{{ end }}
{{ end }}
{{ end }}
然后去修改普罗米修斯程序的prometheus.yml 文件 Alertmanager configuration 中写上127.0.0.1:9093 rule_files: 写上first_rules.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "Windows"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["127.0.0.1:9182"]
再次在普罗米修斯目录新建一个配置文件 名为 first_rules.yml 其中expr: up 为你需要报警的job_name: “Windows”
groups:
- name: node-rules
rules:
- alert: node-up
expr: up{job="Windows"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{$labels.instance}}Instance has been down for more than 15 seconds"
alert:告警规则的名称。
expr:基于 PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在 等待期间新产生告警的状态为 pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations 的内容在告警产生时会一同作为参数发送到 Alertmanager。
summary 描述告警的概要信息,description 用于描述告警的详细信息。
同时 Alertmanager 的 UI 也会根据这两个标签值,显示告警信息。
Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing
第一种:Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。
第二种:Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所 以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。
第三种:Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警 报解除,则将状态转到 Inactive,如此循环。